Профайлинг нагруженных Python-программ: печальная история со счастливым концом
Профилирование - это первое, что должно приходить в голову, когда у нас встаёт вопрос производительности приложения. Если грамотно провести профилирование приложения, то суть проблем произвдительности становится намного понятнее, и фиксы можно создавать уже более осмысленно.
Однако в мире Python с профилированием не всё так прекрасно. Существует несколько инструментов, но все из них обладают определёнными ограничениями.
cProfile и его друзья
Как мы все знаем, в Python есть встроенный профайлер в лице модуля cProfile. Он существует давно, поставляется вместе с интерпретатором, прост в обращении. Разве не это ли нужно для счастья?
Всё было бы славно, если бы не один нюанс. Дело в том, что cProfile - детерминированный профайлер (deterministic profiler). Это значит, что он профилирует все методы. И на вызов каждого метода накладывается некоторое дополнительное время. Достаточно часто это не является проблемой. Но, если мы тестируем приложение, работающее под серьёзной нагрузкой, возникают неприятные спецэффекты.
На днях, запустив профайлер на нагруженный сервис, созданный на основе фреймворка Twisted, я обнаружил странный результат: при вычислении итогового времени работы методов получалось, будто бы больше всего времени (90%) сервис проводил внутри… epollreactor.doPoll. Вот какую картинку показывает grpof2dot (цифра 88.37% справа внизу):
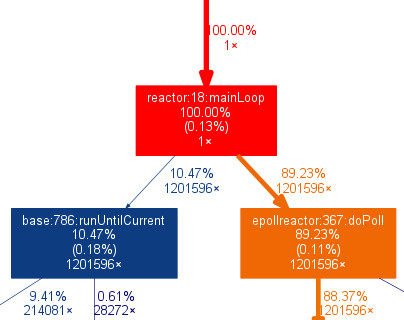
Почему это странно? Потому что системный вызов epoll_wait работает быстро! Приложение не может проводить в нём так много времени. Это подтверждается и независимой проверкой через strace. Обращений к epoll_wait происходит много, но суммарное время, которое тратится на эти обращения, весьма мало.
Но не в том случае, когда мы запускаем программу под детерминированным профайлером! Профайлер добавляет свой overhead на вычисление времени работы метода, сумма этих overhead-ов накапливается и становится больше, чем время работы всех остальных методов. Проблемы тут возникает сразу две:
- Приложение начинает работать под профайлером совсем не так, как без него. Оно действительно больше времени тратит на тупление внутри реактора, а на рабочую логику может выделять меньше времени. Соответственно, у него заметно проседает производительность.
- Результаты профилирования не соответствуют поведению приложения без профайлера. Из его отчёта совершенно неясно, где же на самом деле тратится время.
Конечно, далеко не все Python-программы используют Twisted с его реактором, поэтому данная проблема может быть для них слабо актуальна. Но мне-то что со своим сервисом делать?
Помимо cProfile, в Python-мире существует ещё несколько разномастных профайлеров, неплохой обзор которых есть на хабре, но они нам тоже ничем не помогут: тоже детерминированные, тоже добавляют существенный overhead, да ещё и требуют модификации исходного кода сервиса, т.к. профилируют только участки, помеченные специальными декораторами.
Какие ещё есть варианты? Есть смысл поглядеть в сторону статистических профайлеров.
(Почти) универсальный солдат perf
Это классический представитель семейства статистических профайлеров. Работает по такому принципу: N раз в секунду снимает текущий стек у приложения и запоминает его. Затем из всех собранных стеков можно сформировать общую картину: какие методы попадаются чаще, какие реже. Такой подход не даёт видеть редкие вызовы методов, но зато достаточно хорошо показывает, где происходят основные задержки, а также меньше влияет на производительность профилируемого сервиса (и меньше искажает картину). Я использую для этого FlameGraph, выходит очень наглядно и удобно.
В дополнение, частоту сэмплирования можно задавать какую угодно: хочешь уменьшить нагрузку - снижаешь частоту, хочешь увеличить точность - поднимаешь. Особенно это важно при работе с нагруженными сервисами: рост overhead-а от профилирования может серьёзно искажать само поведение профилируемого сервиса, как мы уже убедились в предыдущей части.
Казалось бы, идеальный инструмент! Но тут возникает новый нюанс: если мы пробуем натравить perf на Python-программу, то увидим не стеки своей программы, а стеки самого интерпретатора Python. perf работает тупо, но честно: “коли мне сказали профилировать интерпретатор, я буду профилировать интерпретатор, а что за код он крутит внутри себя, мне не важно”. Вот только нам от такой информации немного пользы. Разве что можем дополнительно убедиться, что cProfile сильно врёт: показания perf говорят нам, что на epoll тратится вовсе не 90% времени, а какие-то единицы процентов.
Есть ли инструмент, который работает как perf, но при этом позволяет видеть методы Python-сервиса? Как оказалось, есть.
Новая надежда: pyflame
Инженеры из Uber сделали для нас такой инструмент. Он присоединяется к Python-программе с помощью вызова ptrace, считывает состояние из структур интерпретатора и выводит данные в формате, пригодном для построения FlameGraph-ов. Профилирование тоже производится статистически, его частоту можно варьировать. Это именно то, что мне нужно!
Хотя свои недостатки у этого инструмента тоже есть.
Во-первых, готовые бинарники есть только под Ubuntu и Arch. Если Вы используете другой дистрибутив (например, любой RPM-based), придётся расчехлять компилятор и собирать приложение вручную. Но это почти тривиально! Сначала ставим нужные для сборки пакеты:
autoconf automake libtool gcc-c++
Затем можно собрать приложение:
./autogen.sh ./configure make
Если сборка прошла успешно, то в папке src появится файл pyflame, который и будет работать профилировщиком.
После этого можно присоединяться к запущенному приложению и добывать из него стеки!
./src/pyflame -s 60 -r 0.01 <pid> > my_service.flame
Показал бы тут и итоговый flamegraph, но, боюсь, это уже будет нарушать NDA :) Лучше посмотрите примеры из самого PyFlame или попробуйте построить их сами. Просто скажу, что мы здесь получаем именно то, что было нужно: нормальные питонические стеки с указанием частоты попадания в каждый отдельный из них. Чем шире строчка для функции, тем чаще мы в неё попадали, а значит, тем больше времени уходит на её выполнение.
Есть ещё пара важных особенностей, про которые надо знать, применяя pyflame.
- В итоговом графе значительную часть времени может занимать строчка “(idle)”. Как разработчики пишут в документации, это время соответствует тем семплам, когда никакой Python-код не держит GIL (т.е., не выполняется). В это время может происходить другая работа в соседнем потоке, но для
pyflameона не видна. Её можно сделать видимой, если при запуске указать флаг--threads, но на относительно старых ядрах Linux это может приводить к зависаниям профилируемого приложения. Либо включаем опцию на свой страх и риск, либо миримся с наличием(idle), либо отключаем статистику по нему с помощью флага-x. - В некоторых ситуациях, как мне показалось,
pyflameне выводит никаких данных. Скорее всего, это происходит, если профилируемое приложение внезапно завершилось (например было перезапущено). Либо, если профилирование было очень коротким. Отсюда вытекает рекомендация: период профилирования должен быть достаточно длинным (как минимум, несколько десятков секунд). Впрочем, для статистического профайлера это в любом случае необходимо - иначе его результаты будут не особо точными.
Подводя итоги
Я очень доволен, что удалось найти подходящий инструмент для моих задач. Крайне непродуктивно заниматься оптимизацией производительности программы, не имея возможности напрямую видеть результаты этой оптимизации.
Но есть и ещё один полезный урок: даже если кажется, что подходящий инструмент найден, совсем не лишней будет проверка корректности его показаний. Именно такая проверка показала, что cProfile не подходит конкретно в моём случае, и вынудила меня искать альтернативы. Посмотрим, насколько правдив окажется и сам pyflame. Время покажет!